
Checkout for the probable causes and optimization techniques
In this article, we shall walk through a typical AWS serverless architecture and discuss the scaling-related challenges, possible solutions, and optimizations.
It is assumed that you already have working experience with AWS serverless services like API Gateway, Lambda, Secrets manager, RDS, SQS, SNS, and S3.
Table of contents
- Introduction
- Common observations when the system is under load
- Probable cause 1: DB as a stress point or overwhelming downstream databases
- Probable cause 2: throttling of Secrets Manager
- Probable cause 3: throttling of CloudWatch
- Probable cause 4: Lambda timeouts
- Architecture change proposals: change of architecture from synchronous to asynchronous pattern using SQS
- Summary
- References
1. Introduction
Let’s consider an AWS serverless architecture(Figure 01), which is a synchronous serverless application with the below AWS components:
- API Gateway(GW) to expose the end-points to the outside world
- Lambda as a computational layer
- RDS as a data persistence store
- Secrets Manager to store the secure information
- CloudWatch for the aggregation of logs
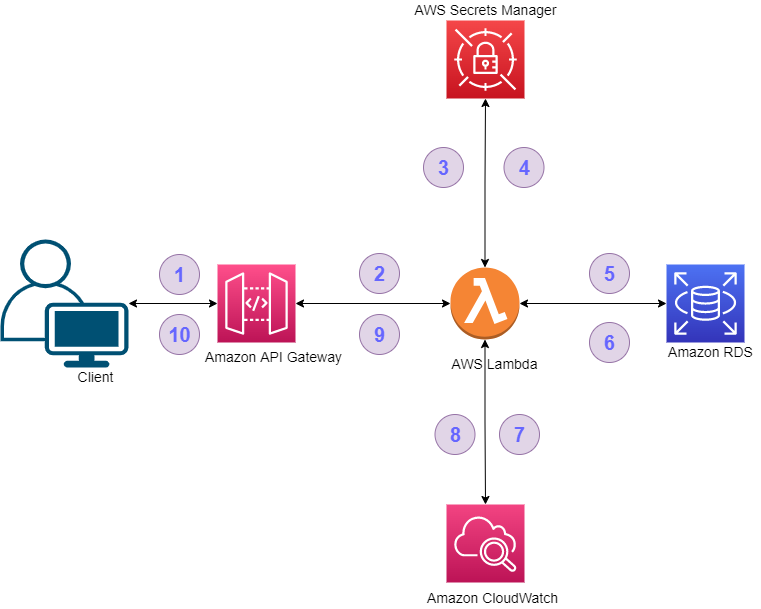
Figure 01: a typical AWS serverless architecture.
A typical AWS serverless architecture, as in figure 01, would work seamlessly without any problems under basic to moderate load conditions. The sequence diagram of the above serverless synchronous architecture is presented in figure 02**.** In figure 02, one can observe that the sender is waiting until all the computations are completed.
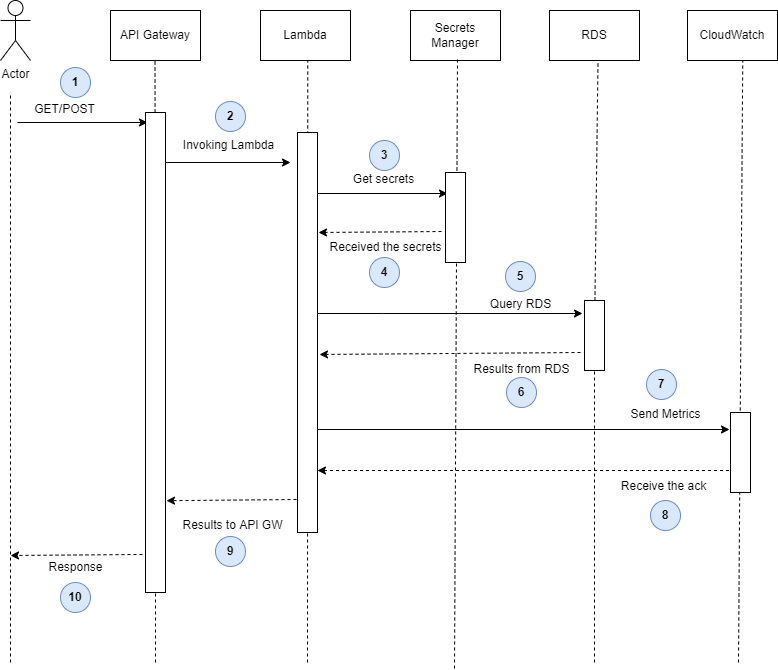
Figure 02: sequence diagram of the architecture presented in figure 01.
2. Common observations when the system is under load
Below are the common observations once the application starts experiencing the requests at scale or if any load tests are performed.
- API Gateway integration timeouts → when the response time exceeds 29 seconds.
- Lambda execution timeout → when Lambda processing time exceeds 15 minutes.
- Lambda-RDS connection failures → too many open connections.
- Lambda throttling → exceeding the Lambda concurrency.
- Secrets Manager throttling → exceeding the allowed limits.
- CloudWatch Metrics throttling → exceeding the allowed limits.
- Increased Lambda billing cost → increased execution times.
- Reduced throughput.
As a result of the above factors, one can start noticing performance degradation. Let’s see the various possible reasons which could be causes for the above observations.
3. Probable cause 1: DB as a stress point or overwhelming downstream databases
Once the load on the downstream database is increased by many folds, the query execution times would also increase. If a request takes 500 ms to complete under average load conditions, the same request may take longer than 500 ms under heavy load conditions.
DB load impacts the query performance → increased Lambda execution time.
Higher Lambda execution time would have the following effects:
- Increased Lambda billing cost.
- It could cause API GW timeouts if increased beyond 29 seconds.
3. Lambda timeouts, if increased beyond 15 minutes.
A symptom to identify this possible case would be an increased error code 500 as API GW response.
Optimization possibilities
- Amazon RDS Proxy: this will do the connection pooling. Also, a proxy can use the DB credentials directly by connecting to Secrets Manager. This would also prevent the application from bothering about handling secrets.
- Using RDS Aurora Serverless API
- If possible, consider migration to DynamoDB
4. Probable cause 2: throttling of Secrets Manager
AWS Secrets Manager will throttle at 5000 req/sec, i.e., DescribeSecret and GetSecretValue, combined.
Check out the source code to see if the code to fetch the secret from Secret Manager and database connection creation is inside the lambda_handler method or not. If yes, then there is a call to the Secrets Manager, and a new database connection is created for every Lambda request, even in the warm execution scenario. This would increase the cost, increase the latency, and can lead to the throttling and exhaustion of database connections.
Connection creation inside the lambda_hanlder
Optimization possibilities
To optimize this, use the warm execution context and move the connection creation line outside the lambda_handler as below. With this, except in the case of cold execution of Lambda, fetching of RDS secret and RDS connection creation will not happen, and these can be utilized by the subsequent requests.
Connection creation outside of the lambda_hanlder
5. Probable cause 3**: throttling of CloudWatch**
CloudWatch PutMetricData can handle 500 transactions/second above this value, CloudWatch would throttle the requests. Below is the sample piece of code which would put metrics into CloudWatch.
Sending custom metrics data to CloudWatch from Lambda
Optimization possibilities
To optimize this, use Embedded Metric Format(EMF). This would instruct CloudWatch Logs to extract metric values embedded in structured log events automatically. Metrics are written into stdout in a standardized format, then CloudWatch publishes them to CloudWatch metrics asynchronously. It is an open-source library on GitHub. The above piece of code can be written as below using this library.
Lambda with embedded metrics
6. Probable cause 4: Lambda timeouts
Below are optimization possibilities that one can optimize Lambda and make it faster.
Optimization possibilities
- Initialize always used resources at the start to take advantage of the warm start.
- Lazily initialize seldom used resources inside the methods.
- Load the dependencies only when needed this will reduce the INIT time during the cold start.
- In Lambda, wait parallelly — not serially. Take advantage of vCPUs and use multi-threading.
- Leverage StepFunctions when there is a need to wait.
# Reading the Lambda environment values
rds_db_name = os.environ['APP_RDS_DB_NAME']
rds_user_name = os.environ['APP_RDS_USERNAME']
rds_pwd_arn = os.environ['APP_RDS_PASSWORD_ARN']
def lambda_handler(event, context):
# Fetching the password from secrets manager with ARN
password = secretsManager.get_secret_value(secretId = rds_pwd_arn)
# RDS coonection creation
rds_conn = opendConnection(rds_db_name, rds_user_name, rds_pwd_arn)
....
/* application logic */
....7. Change proposal: change of architecture from Sync to Async pattern using SQS
Change prosal of architecture can be categorized into two types of systems as below:
Type 1: it is enough if the sender is acknowledged that the request is received and saved successfully, processing can be done in an async way.
Type 2: sender needs the response with results back.
Let’s see how we can achieve the above two async patterns.
Type 1: response doesn’t need results back
In this category, the sender does not need the processed results back. Hence, we can detach the processing part of the workflow and do it in an asynchronous way.
To achieve the asynchronous behavior, we need a queue to persist the incoming requests, AWS service Simple Queue Service (SQS) is introduced.
In figure 03, the architecture is presented. Let's name the first part the “requests-saving” stage and the second part the “processing stage.” Figure 04 is the sequence diagram for figure 03.
Requests-saving stage:
- It will receive the incoming requests via API GW and will pass them on to Lambda-1.
- Lambda-1 may do any pre-processing and save the request to SQS. If there is no pre-processing is required, then API GW can directly integrate with SQS.
- Once the request is saved to SQS, Lambd-1 can return a successful response back to GW, and the sender is notified.
Processing stage:
- The link between the requests-saving stage and processing-stage is SQS, which decouples both stages.
- The requests(or messages) from SQS can invoke Lamdba 2 in a synchronous manner in two ways: event source mapping or custom code in Lambda-2 to fetch messages from SQS. Tip: batch size, batch window, and many more settings can be configured while reading messages from SQS.
- Now Lambda-2, Secrets Manager, RDS, and CloudWatch would resemble the architecture depicted in Figure 01.
- One extra thing that would happen is that once the message is processed successfully by Lambda-2, the respective message needs to be removed from SQS. This would happen automatically in case of event source mapping and in case of custom code, this need to be done explicitly.
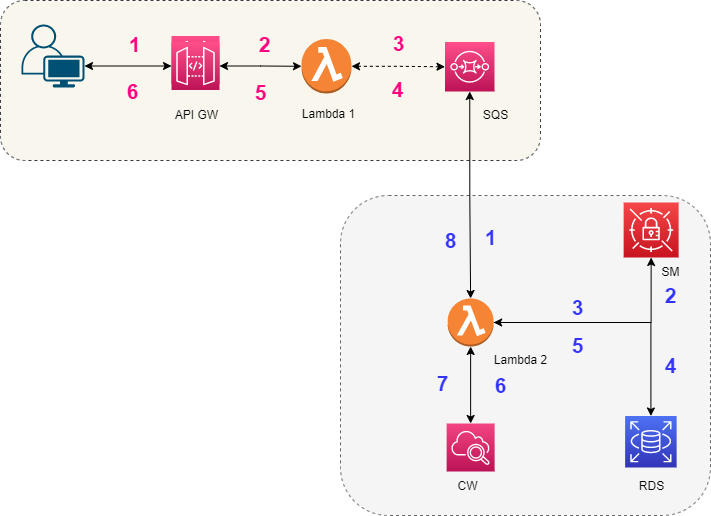
Figure 03: async system architecture when the response with results is not needed.
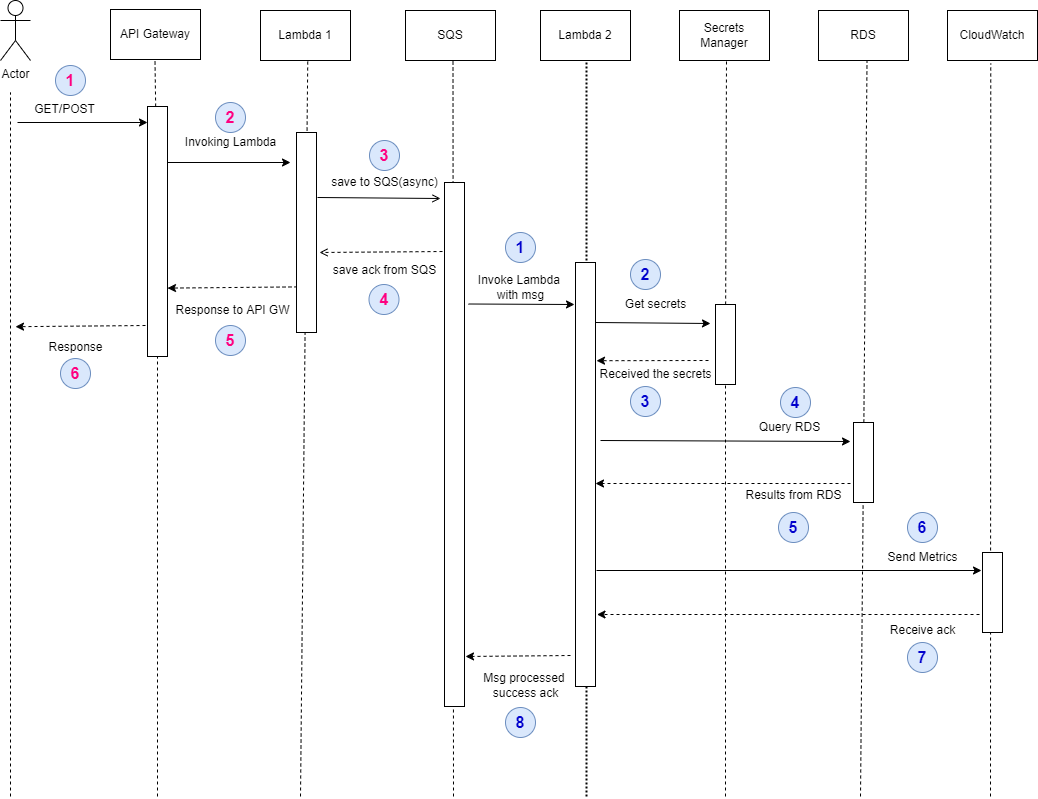
Figure 04: sequence diagram of figure 02, when a response with results is not needed.
Type 2: response needs results back
In this case, the request expects a resultset in the response. In order to fulfill this requirement, a few more components have been added.
Simple Notification Service (SNS): it is a serverless notification service. More than one subscriber can be subscribed to the SNS. Once there is a notification SNS would send it to all the valid subscribers.
Simple Storage Service(S3): it is a serverless object storage service used to store the resultset.
Figure 05 is the architecture of the Type 2 use case. Here, the idea of Type 1 is extended with an extra stage of results-storage. Once the Lambda-2 completes the processing successfully, it would send the resultset to the pre-configured S3 bucket and path and send a notification(with S3 bucket name and path to resultset file) to the pre-configured SNS.
The pre-requisite is the sender should have already subscribed to the SNS.
Once the sender receives the notification from SNS, it can again make a GET request to read the results from S3. This additional layer needs to be implemented by the sender in case of considering this solution.
The sequence diagram for the type 2 architecture is presented in figure 06.
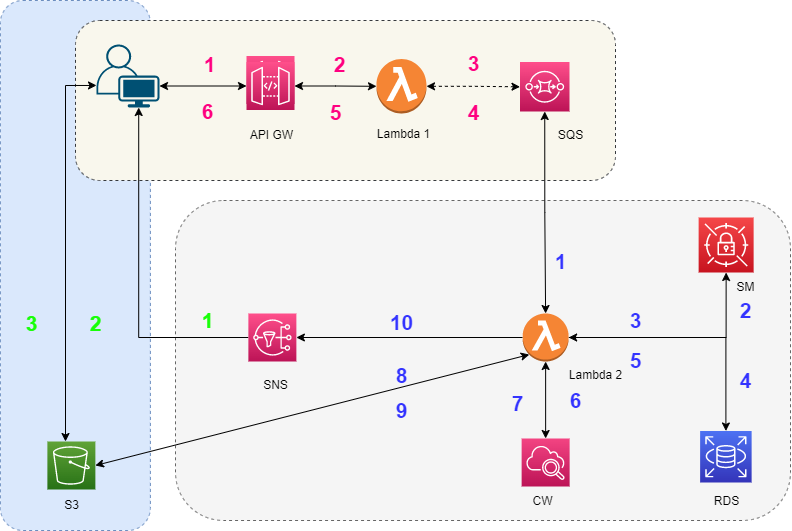
Figure 05: async system architecture when the response with resultset is needed back.

Figure 06: sequence diagram of type-2 architecture when the response with resultset is needed back.
8. Summary
In this article, a typical AW serverless architecture is considered, and the probable scaling-related challenges are discussed. The probable causes have been discussed in detail, along with optimization solutions are presented. In the last section, proposals are made to convert the synchronous to the asynchronous pattern. Two types of use cases were looked at: first, where the response doesn’t require the resultset back, and second where the response requires the resultset back. Both the use cases were discussed in detail, along with the supporting architectural and sequence diagrams.
And there we have it. I hope you have found this useful. Thank you for reading.
9. References
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/data-api.html [Data API for Aurora Serverless v1]
https://www.youtube.com/watch?v=dzU_WjobaRA [Serverless at scale: Design patterns and optimizations by Roberto Iturralde]
https://aws.amazon.com/dynamodb/[Amazon DynamoDB home page]
https://docs.aws.amazon.com/secretsmanager/latest/userguide/reference_limits.html [AWS Secrets Manager quotas]
https://docs.aws.amazon.com/lambda/latest/operatorguide/execution-environments.html#function-warmers [Understanding how functions warmers work]
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_limits.html [CloudWatch service quotas]
https://aws.amazon.com/cloudwatch/pricing/ [Amazon CloudWatch pricing]
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch_Embedded_Metric_Format_Specification.html [Specification: Embedded metric format]
https://github.com/awslabs/aws-embedded-metrics-node [aws-embedded-metrics library in GitHub]
https://aws.amazon.com/sqs/ [AWS Simple Queue Service]
https://medium.com/@pranaysankpal/aws-api-gateway-proxy-for-sqs-simple-queue-service-5b08fe18ce50 [API Proxy for SQS]
https://docs.aws.amazon.com/lambda/latest/dg/invocation-eventsourcemapping.html [Lambda event source mappings]
More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord.
Comments