
Managing Asynchronous Workflows with a REST API
by Scott Gerring | on 11 MAY 2021 | in Amazon API Gateway, Architecture, AWS Lambda, AWS Step Functions | Permalink | Share
While building REST APIs, architects often discover that they have particular operations that have to run in the background outside of the request processing scope. Some of these may be “fire and forget”—there is no need to report back to the client—for example, when initiating a shipment. For others, the client may need a response, but can’t get it in the original request because of the long processing time, like if they are generating a complex report. This requires pulling the relevant data together and rendering a PDF, which can be a time-consuming process, often better performed asynchronously.
In this post, we will show you common patterns for handling these operations, their advantages/disadvantages, and their typical AWS serverless implementations. We will use the example of a PDF-generation process mentioned earlier. An AWS Lambda function will represent the report generation process itself, but any other AWS service, such as Amazon Elastic Container Service (Amazon ECS) or batch, can be used as well.
The REST API
For our example PDF report, we model the outcome of the background process as a REST resource. Regardless of which pattern we follow to report back to the client, we’d create the job the same way:
POST /api/v1/report
....
{
"reportDate": "2021-01-01",
"reportType": "COFFEE_SALES"
}
Some elements of the response are common to all of the patterns we will look at:
- A
HTTP 201 / Created, with theLocationheader set to the unique, and hierarchical identifier (URI) of the new object (for example,Location: /api/v1/report/123). - The contents of the report object will be returned in the body of the response. This includes the fields sent by the client, plus any others that cannot be set directly—for instance, report generation status.
A response for our report generation system might look like this:
HTTP/1.1 201 Created
Location: /api/v1/report/
....
{
"reportDate": "2021-01-01",
"reportType": "COFFEE_SALES",
"completed": false
}
The patterns: polling, webhooks, and WebSocket APIs
1. Polling
We built a simple system to manage these operations by allowing the client to poll a REST resource to check the status of its request. We implemented this pattern using Amazon API Gateway, Amazon DynamoDB, and AWS Step Functions:
- The client sends the request (shown in the previous section) to the server to begin the operation.
- The server creates a new item to represent the report and returns the resource’s URI to the client. In this example, we built a storage-first API using the direct integration between API Gateway and DynamoDB to create the record without writing any code of our own. In addition to the report fields sent by the client, the resource gains a “completed” field to indicate whether the report has been successfully generated.
- The asynchronous process begins on the server side, triggering a Lambda function attached to the table’s DynamoDB stream. This Lambda function performs the background task: it generates the report, storing it in the output Amazon Simple Storage Service (Amazon S3) bucket.
- Finally, the Lambda function updates the DynamoDB table, marking the report as complete and supplying the S3 URL that the report can be retrieved from.
During this process, the client polls the URI returned by the server. The server returns the status of the report as part of the response:
GET /api/v1/report/523
{
"reportDate": "2021-01-01",
"reportType": "COFFEE_SALES"
"completed": true,
"pdfUri": "https://s3.eu-central-1.amazonaws.com/.../report-123.pdf"
}
In the polling pattern, the client must decide how frequently to poll the URL and when to give up. One common choice is exponential backoff, which increases the interval between checks until a maximum interval is reached or the response is received.
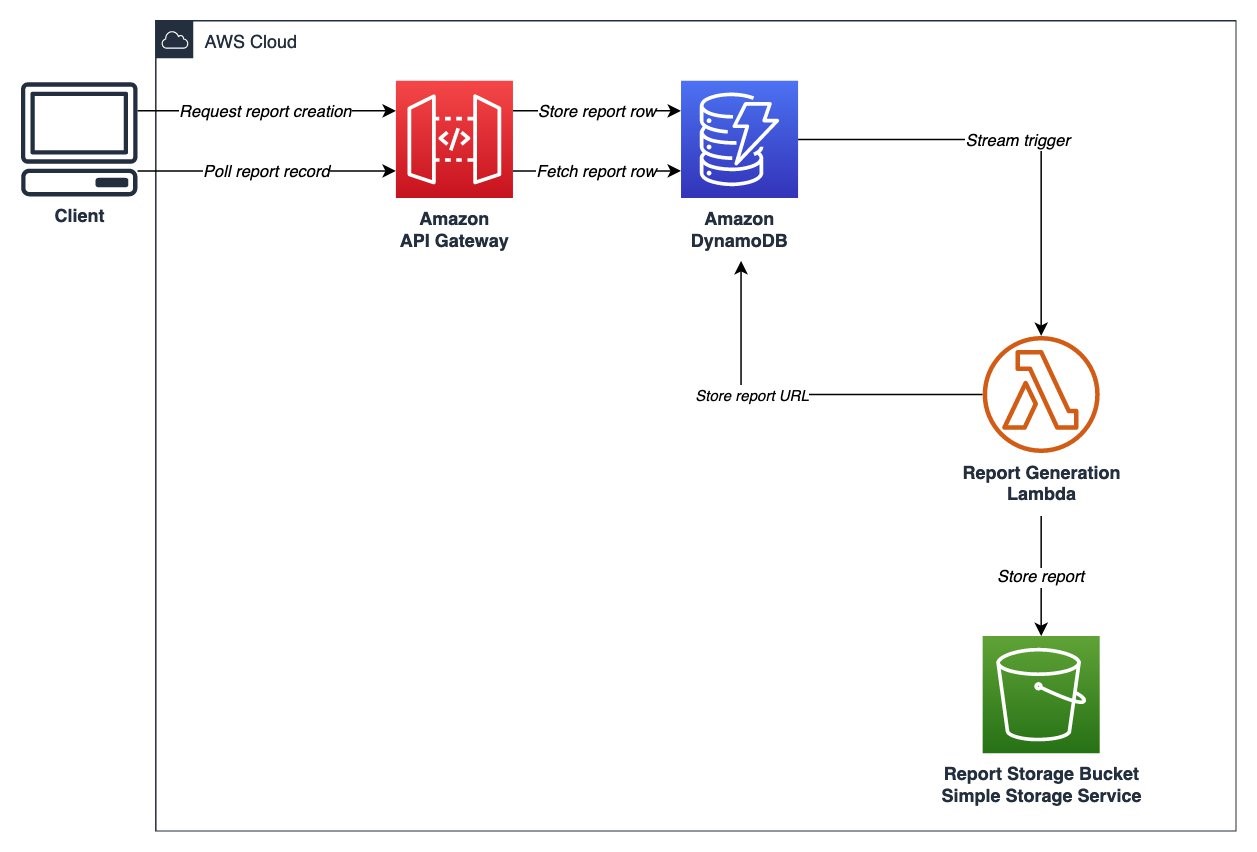
Figure 1. Serverless polling architecture
2. Webhooks
If you’re building an API used between services and not a browser and a service, webhooks are another option. Using webhooks, the caller provides a callback URL that is called back when the asynchronous operation is complete. You can think of this as refining the polling strategy. The caller can still poll for the status and retrieve the entity via the REST API as usual. However, it can also use a webhook to get the updated status without the polling.
The URL can either be provided as part of the request itself, or it can be pre-registered for the particular client’s identity. In this example, we use Amazon Simple Notification Service (Amazon SNS) and assume that the client has pre-registered a web service endpoint subscription to receive the callback. Using Amazon SNS simplifies retries and delivery failures, and establishes trust with the client’s endpoint. It can also be used to send notifications to a client via SMS or email.
When it’s practical to host a callback endpoint on the client side, it offers you a simple and effective option that is often used for server-to-server communication.
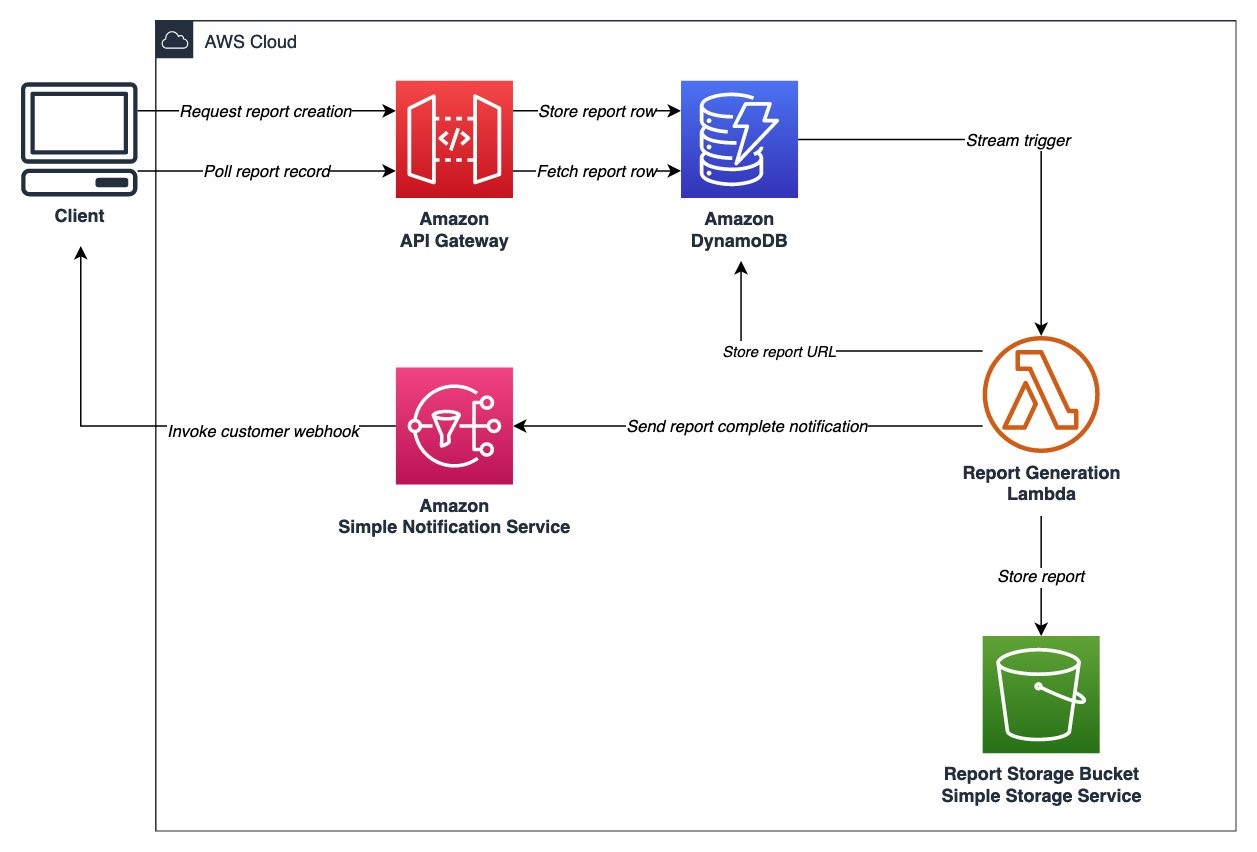
Figure 2. Serverless webhook architecture
3. WebSocket APIs
If the API needs to support browser-based clients and the response latency is important, you may not be able to use polling or webhooks. Instead, WebSocket APIs can be used to allow the server to push a message back to the browser as soon as the work is completed. The client sends the initial POST to create the work normally, and it receives a WebSocket API URL to listen on as part of the response. As an example, this could be provided as part of a nested “_links” object on the response body, which would include the new object’s ID in a URL parameter. The flow looks like this:
- The client sends a request to the server to begin the operation.
- The server responds with the typical report creation response we showed earlier, in addition to a URI to a WebSocket API to listen to progress. Simultaneously, the asynchronous process is started by starting the associated Step Function, once again running our report generation Lambda function.
- We can also wait for the client to connect to the WebSocket API before advancing to the final step, which sends the generated report to the WebSocket API.
- The client connects to the WebSocket API.
- The Step Function advances to the final step and delivers the report model via the WebSocket API to the client.
This approach provides a low-latency option for interactive, browser-based clients, at the expense of more work on the cloud side. Step Functions are required to synchronize the WebSocket API connection and the completion of the background task.
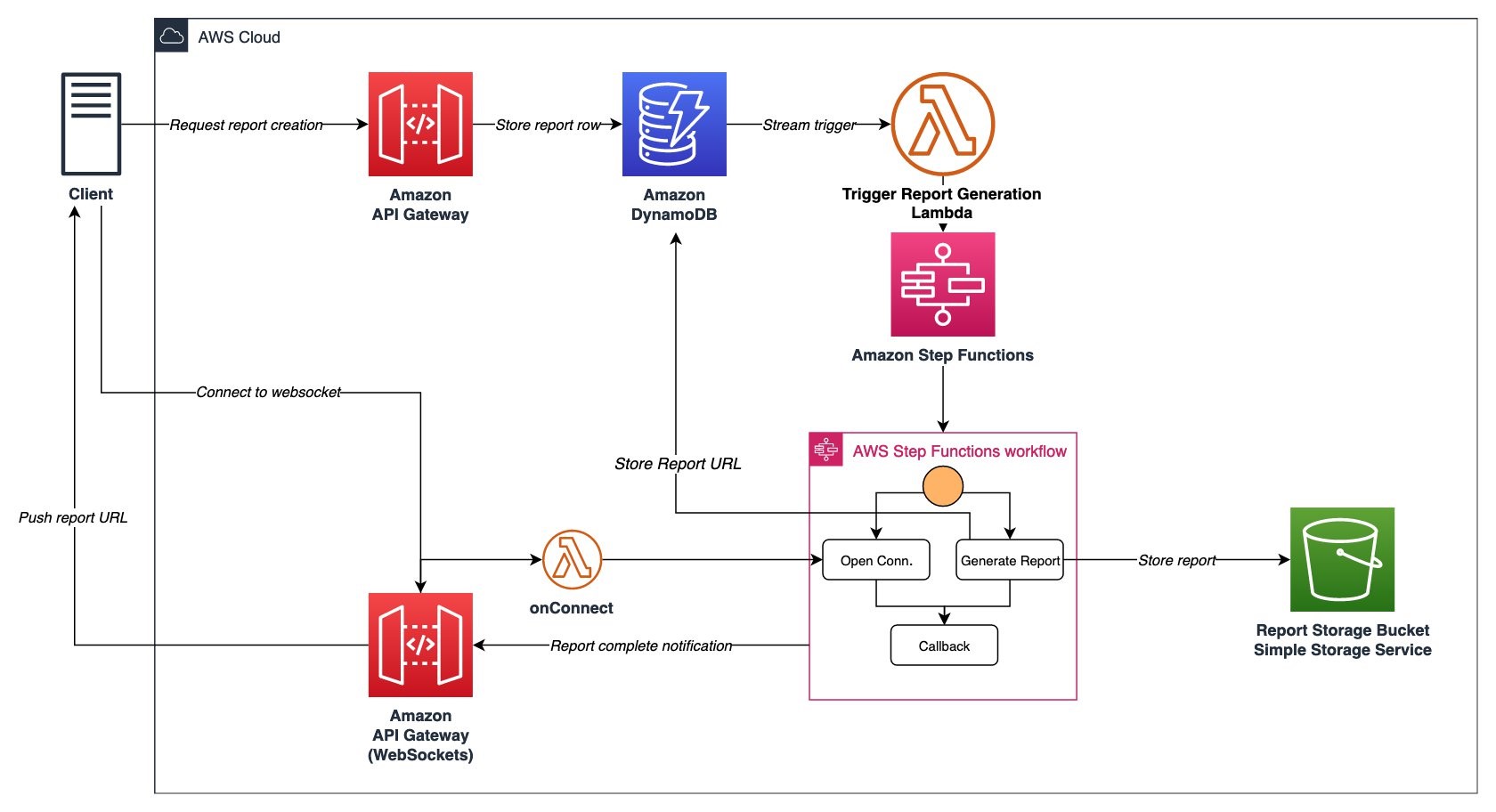
Figure 3. Serverless WebSocket API architecture
Alternate strategies
If you aren’t tied to REST, GraphQL and the AWS AppSync service offer another possibility. Using GraphQL subscriptions, a client can subscribe to the results of an operation. Additionally, the server can push the result back to the client at some point in the future. GraphQL and REST APIs are different technologies with their own set of trade-offs, and it is important to consider your overall API design strategy as a whole.
Conclusion
In this post, we looked at how we can build an asynchronous background process into a REST API. The following table summarizes the advantages and disadvantages of each pattern. Understanding the options you have to build such a system with AWS serverless solutions is important to choosing the right tool for your problem.
Pattern
Advantages
Disadvantages
Polling
-
Simple AWS implementation
-
Well-understood patterns
-
Resources wasted for polling
-
Increased client complexity
-
Suboptimal response time
Webhook
-
Fast notification
-
Good for server-to-server communication
-
Caller must host an API endpoint
-
Extra effort to register and call webhooks
WebSocket API
-
Fast notification
-
Works well with browser-based clients
-
Most complex implementation
Related information
To learn more, check out the following links:
- SNS – Fanout to HTTP/S Endpoints discusses using SNS to call back webhook endpoints
- From Poll to Push: Transform APIs using Amazon API Gateway REST APIs and WebSockets provides a deeper dive into the WebSocket API option
- Working with WebSocket APIs
- Invoke AWS services directly from AWS AppSync provides an example of a long-running operation enabled via GraphQL subscriptions
Comments