
serverless is not just about FAAS (just lambda)
when we talk about serverless architecture, it goes way beyond Function as a Service (FaaS) like AWS Lambdas.
Two of the reasons why Lambdas are so attractive are their auto-scale (in & out) capability and their pay-per-use pricing model. In order to leverage these capabilities and reach the full benefits of a serverless architecture, we need our other infrastructure components to have the same flexibility.
What would such an architecture look like on a web project?
At Theodo, we’re loving serverless and using the technology on more and more projects. Some services and patterns start to be used extensively. So we decided to share our architecture best-practices for a web application. If you are new to serverless and looking for a high level guide answering those questions, you’ve come to the right place!
Direct and brutal spoiler (don’t be afraid, we’ll dive into each aspect):

On the above diagram, a block represents a typical and clearly delimited domain or technical feature that could be found in most serverless architectures. They don’t necessarily represent micro-services, or stacks in CloudFormation lingo (we will get into that below).
We recommend to go full AWS with event-driven micro-services written in Typescript
Our objective is to have a robust fully managed system with a comfortable developer experience. In order to achieve this we go for:
Amazon Web Services
Node in TypeScript
JavaScript is one of the most popular programming language worldwide, therefore it has quite a huge community (see those GitHub stats)! The serverless world does not differ too much from this observation, according to Datadog, 39% of all deployed Lambdas currently run JavaScript, even though Python leads with 47%. TypeScript takes the language a step further and adds a great extra layer of protection. And finally, JavaScript in Lambdas works great for the vast majority of use cases!
Use serverless framework or AWS CDK
The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework to define your cloud application resources using familiar programming languages. Provisioning cloud applications can be a challenging process that requires you to perform manual actions, write custom scripts, maintain templates, or learn domain-specific languages. AWS CDK uses the familiarity and expressive power of programming languages for modeling your applications. It provides high-level components called constructs that preconfigure cloud resources with proven defaults, so you can build cloud applications with ease. AWS CDK provisions your resources in a safe, repeatable manner through AWS CloudFormation. It also allows you to compose and share your own custom constructs incorporating your organization's requirements, helping you expedite new projects.
The Serverless Framework
It does most of the basic Infrastructure as Code (IaC) heavy lifting (on top of CloudFormation). Define a Lambda reacting to a HTTP event, the Serverless Framework will automatically deploy the related API Gateway resource and corresponding route along with the new Lambda. And when we are reaching the framework limits, and want a more complex service configuration, we can simply add some CloudFormation.
Proud advertisement: We believe so much in the Serverless Framework at Theodo that we decided to become an official partner!
Fine-grained lambda functions
A Lambda is a function. It has one job and does it well. Our front-end needs to retrieve a list of items? Make a Lambda for it. We need to send a confirmation email after a user was registered? Make another Lambda for it. Of course some specific code (like data entities) can be factorised and shared in a dedicated utilities folder, but pay a very close attention to this code, because any change will impact all related Lambdas and as Lambdas can be tested and deployed independently, we may miss something (TypeScript to the rescue here).
Split in Micro-services
To not have teams stomping on each other, to not have a huge package.json and serverless.yml (CloudFormation has a 500 resources limit), a crazy long CloudFormation deploy time, in order to find ourselves better in our codebase and to enforce clear responsibilities between our Lambdas: we define boundaries splitting our project in Micro-Services.
write your own microservices may be nestjs typescript that can be deployed as a single lambda, its more like lambda as a microservice where api gateway is a proxy for all requests to lambda apis
We recommended earlier to go full JavaScript, but there are many reasons you might want to use another language, or maybe you want to migrate progressively to serverless in JavaScript: the extreme advantage of micro-services in serverless is that you can very easily mix technologies in your architecture while still maintaining an easy and coherent architecture with agnostic interfaces between micro-services.
Communicating in an Event-driven manner
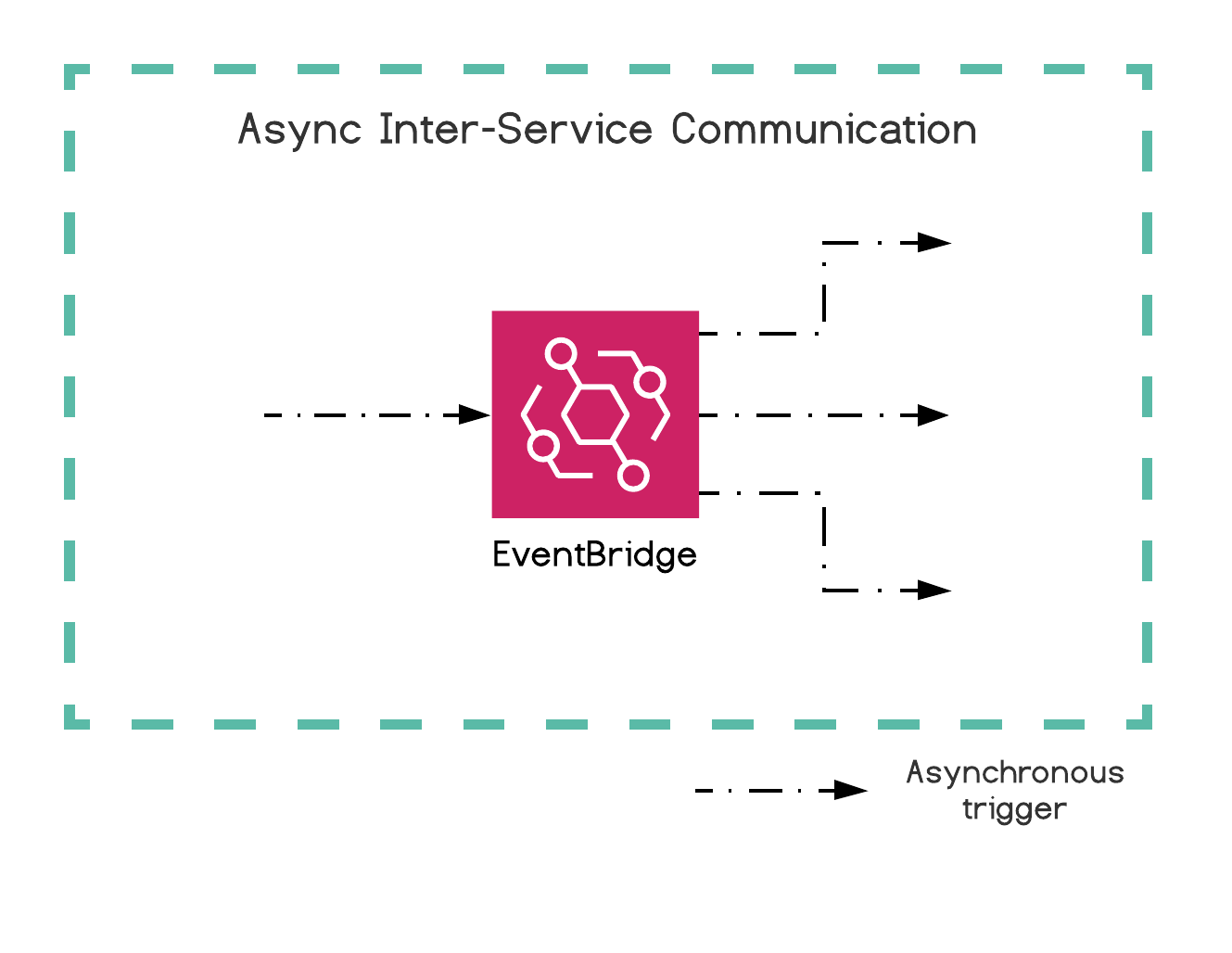
Those micro-services need to be fully independent, if one is down, or if we are making breaking changes in another, the impact on the rest of the system should be as limited as possible. To help with that, Lambdas communicate with one another only through EventBridge, a serverless event bus. In this article
Amazon EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale using events generated from your applications, integrated Software-as-a-Service (SaaS) applications, and AWS services. EventBridge delivers a stream of real-time data from event sources such as Zendesk or Shopify to targets like AWS Lambda and other SaaS applications. You can set up routing rules to determine where to send your data to build application architectures that react in real-time to your data sources with event publisher and consumer completely decoupled.
Each kind of feature requires a certain serverless architecture with specific AWS services
Now that we have set the context, let’s go over each architecture block shown on the above daunting diagram, detailing what are the most serverless-y services to find in AWS.
Frontend (development)
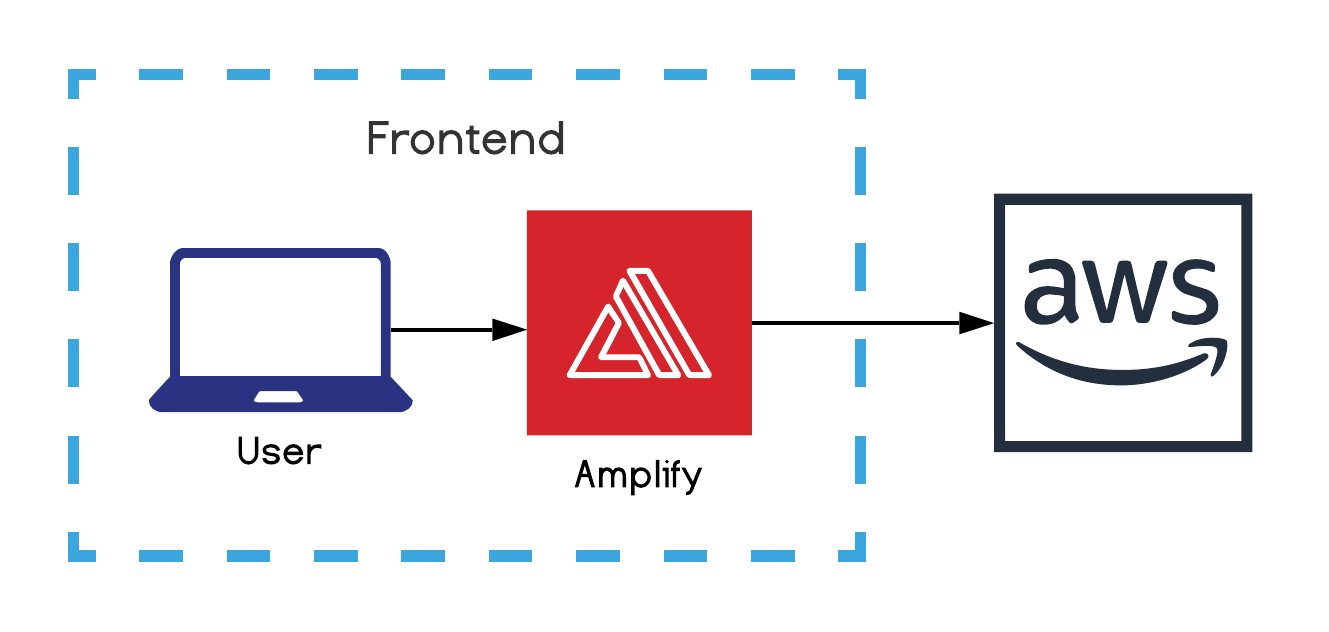
Our shiny serverless backend has somehow to feed a frontend. To ease our frontend development coupled to AWS, we take advantage of Amplify.
Amplify is several things: a CLI tool, an IaC tool, an SDK and a set of UI components. We leverage the frontend JS SDK to make integration with resources (e.g. Cognito for authentication) deployed via other IaC tools (like the Serverless Framework) faster.
Website hosting S3 is good at it with cloudfront
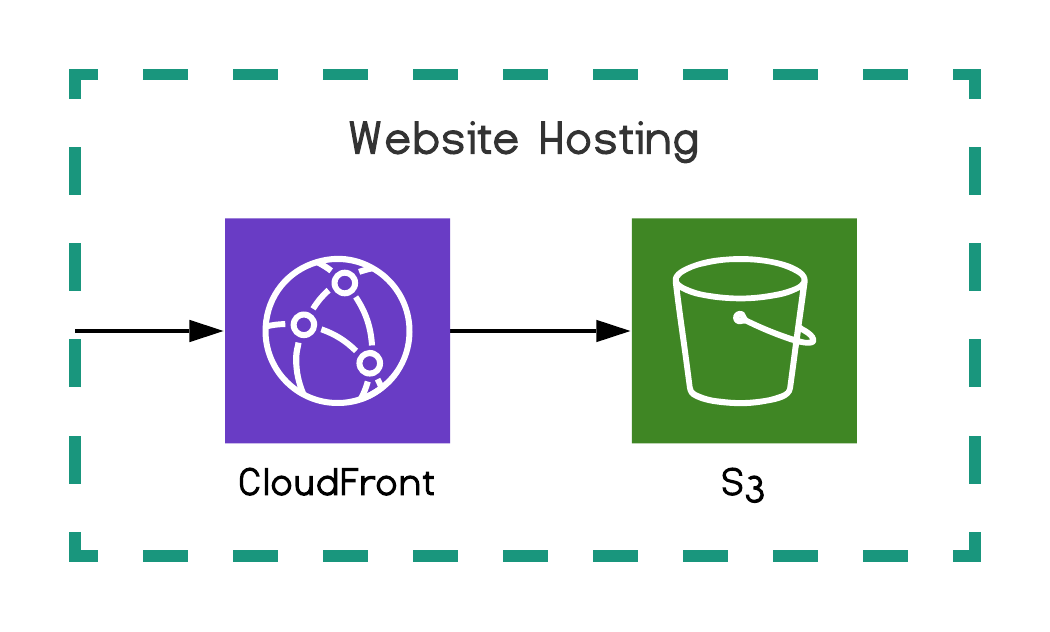
Most of today’s websites are Single Page Applications (SPA), which are fully featured dynamic applications packaged in one set of static files downloaded by the user’s browser at first URL access. In an AWS environment, we host those files on S3 (a file storage) exposed through CloudFront (Content Delivery Network (CDN)).
That being said, the trend is clearly leaning toward Server(less) Side Rendering (SSR) websites like Next.js. To set-up a SSR website in serverless we take advantage of Lambda@Edge within CloudFront. This allows us to do server-side rendering with Lambdas as close as possible to our end users. Check-out this article to dive in the topic.
Domain and certificate
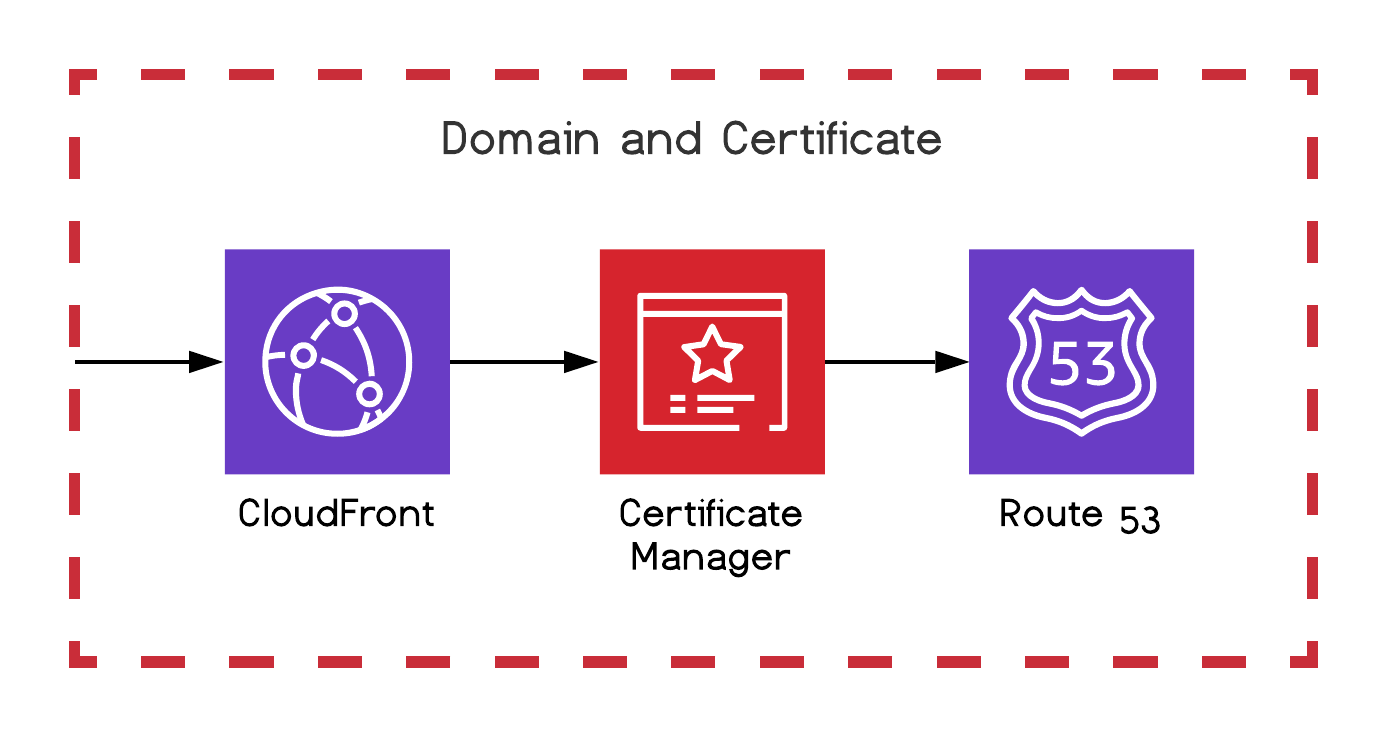
For our website we want something better than the raw auto-generated S3 URL, to do that we generate and bind our certificates to CloudFront with Certificate Manager, and manage our domains with Route 53.
Business API

Now, our website has to get in touch with a back-end to retrieve and push data. To do so we use API Gateway to handle the HTTP connections and routes, synchronously triggering a Lambda for each route. Our Lambdas contain our business logic communicating with DynamoDB in order to store and consume data.
As said above, we are event-driven, which means that we quickly reply to our user, and behind the scene continue to treat the request asynchronously. DynamoDB for instance exposes streams which can asynchronously trigger a Lambda to react on any data change. Most serverless services have a similar capability.
Asynchronous tasks

Our architecture is event-driven, so a lot of our Lambdas are asynchronous and triggered by EventBridge events, S3 events, DynamoDB Streams, etc. We could for instance have an asynchronous Lambda responsible for dispatching a welcome email on a successful sign-up.
Failure handling is critical in a distributed asynchronous system. So for async Lambdas, we use their Dead Letter Queue (DLQ) and pass the final failure message first to Simple Notification Service (SNS) then passing it to Simple Queue Service (SQS). We have to do that for now because it’s not yet possible to attach SQS directly to a Lambda DLQ.
Event driven design is full of async tasks like
- lambda does something and push sns events
- lambda process a file and send event to SQS
Back-end to front-end push (Acknowledge the front end about state change)

With asynchronous operations, the frontend can no longer just display a loader while waiting for an XHR response to come. We need pending states and data push from the backend. To do so we take advantage of the WebSocket API of API Gateway, which keeps the WebSocket connection alive for us and only triggers our Lambdas on messages. I wrote an article deep-diving why we go for WebSocket compared to other solutions and how to implement it.
File upload
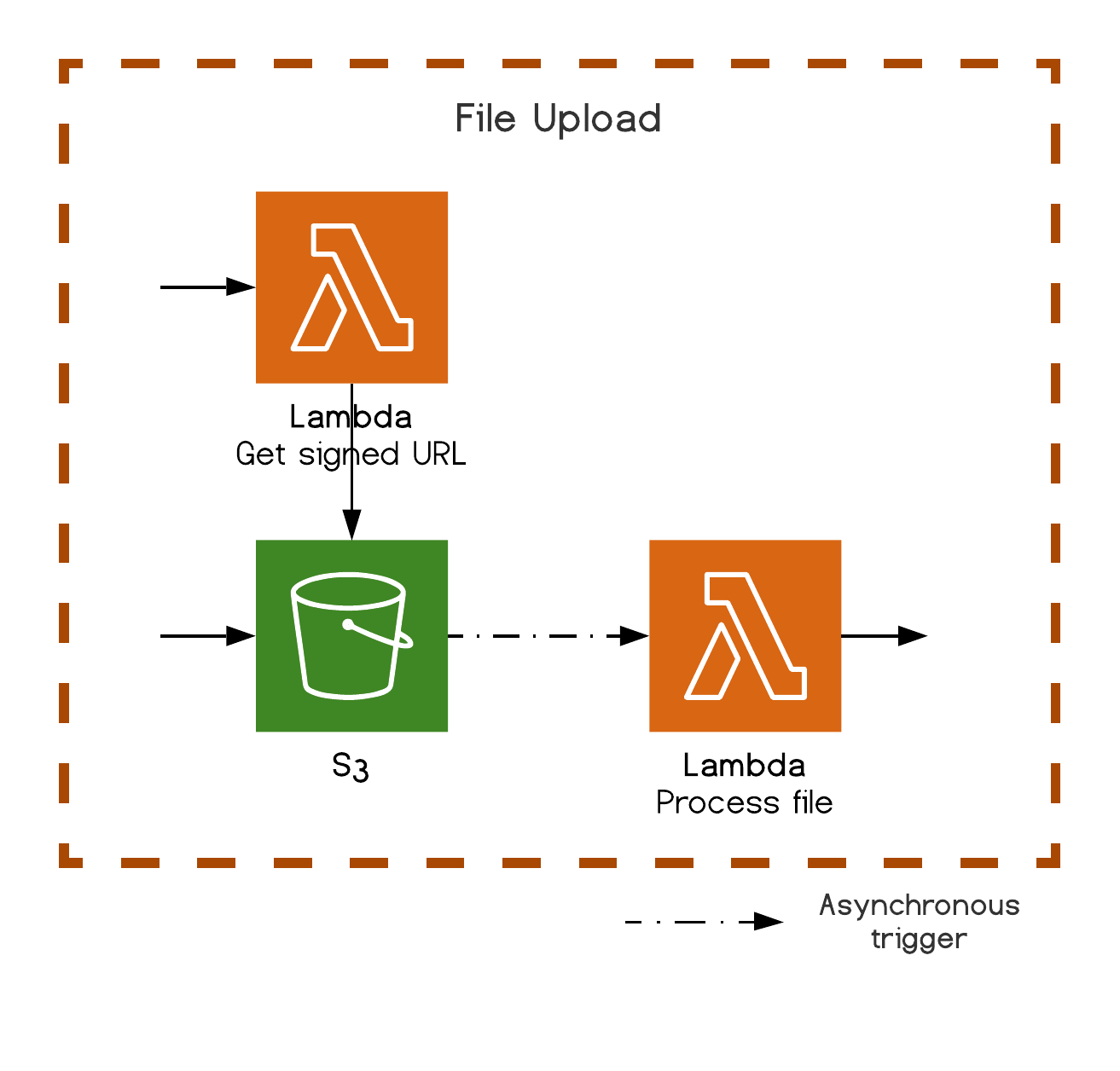
Instead of handling the file upload stream from a Lambda, which might get costly, S3 offers the possibility for Lambdas to generate a signed (secured) upload URL that will be used by our front-end to directly upload the file to S3. As most AWS services, the nice part is that another asynchronous Lambda can listen to a S3 file change event to handle any subsequent operations.
Users and authentication
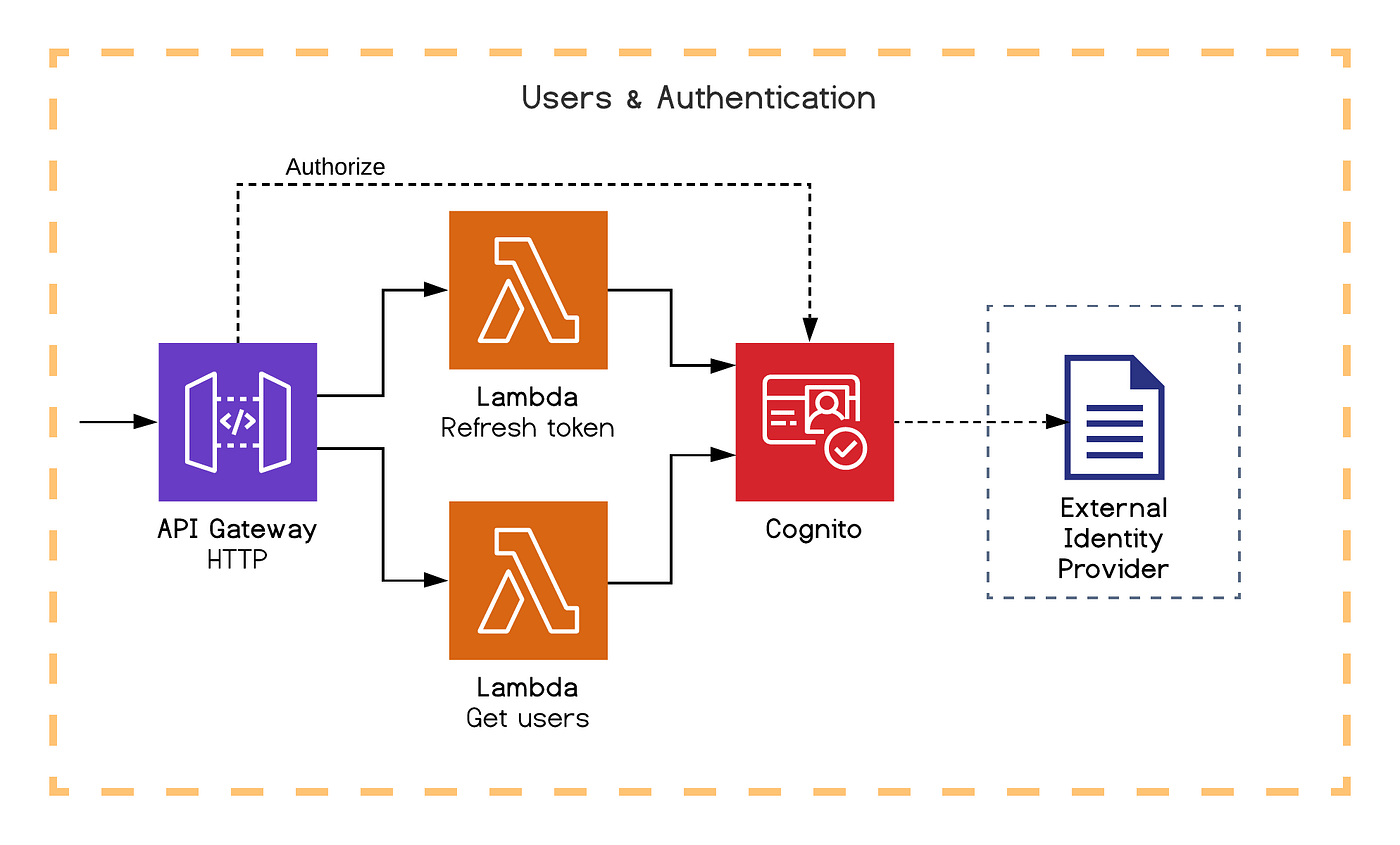
Cognito has everything we need: authentication, user management, access control and external identity provider integration. Although known for being a tad complicated to use, it can do so much for us. And as usual, it has a dedicated SDK to have Lambdas interact with it, and can dispatch events to trigger Lambdas.
In our example, we illustrate the possibility to bind native Cognito authorizers to our API Gateway routes. We also exposed a Lambda to refresh authentication tokens and another Lambda to retrieve a list of users.
One warning though, Cognito is not yet meant for being the goto database for managing your entire user entity, there are some limits like for instance the number of attributes you can have. If you need some flexibility, you will prefer storing custom attributes in DynamoDB.
State machine (Step functions)

In some situations, our logic and data flow might get quite complicated. Instead of operating this flow manually directly inside our Lambdas, hence having a hard time following and structuring what is happening, AWS has a service just for us: Step Functions.
We declare our state machine through CloudFormation: every subsequent steps and states, every expected or unexpected results, and attach to those steps some native actions (like wait or choice) or a Lambda (among several integrations). We can then see our machine run live and visually (with logs) through the AWS interface. At each of those steps we can define retry and failure handling.
further detailed the service in this article.
To give a more concrete example, let’s say we want to send an email campaign with a SaaS and make sure that this campaign has been sent:
- Step 1 - Lambda: asks the SaaS to send an email campaign and retrieves a campaign id
- Step 2 - Task Token Lambda: gets a callback token from the Step Function, links it to the campaign id, then waits for a callback from the SaaS
- Step 3 (outside the flow) - Lambda: called by a hook from the SaaS on campaign status change (pending, archived, failed, success), resumes the flow with the campaign status using the associated callback token
- Step 4 - Choice: based on status, if the campaign is not yet successful, back to step two
- Step 5 (final) - Lambda: on campaign sent, updates our users
This article explains well how Task Tokens work.
Security

Identity & Access Management (IAM) is here to help us manage with fine granularity any AWS access, whether they are developers, CI/CD pipelines or AWS services calling each other. It’s daunting at first, but it has the advantage of being pretty advanced and refined, asking us to think well about every micro action that a specific “consumer” should be allowed to do. Which means that every layer of our infrastructure is protected by default.
Regarding very sensitive data, like a SaaS api key, we safely store it in the Parameter Store of Systems Manager. And request them from inside our Serverless and CloudFormation files, or even from within our code with the associated SDK. It’s useful to mention that Secrets Manager does a similar job. And Key Management Service (KMS) is here to help us manage our encryption keys.
Monitoring

Cloudwatch is the de facto monitoring service. All AWS services have basic automatic metrics and logs sent to CloudWatch to give us some basic informations. We can go much further than that: send custom metrics and logs, create dashboards, trigger alarms on thresholds, make complex queries to dig through the data and display it in custom graphs.
We are still on the lookout for other options. X-Ray for instance, whose objective is to track requests end-to-end through our entire distributed system, then represent it in a very visual and dynamic way. Only that at the moment this tracking gets lost because some services like EventBridge (which is central in our architecture) are not yet supported. Another service, ServiceLens, builds on top of X-Ray and CloudWatch, and looks terrific. There are also some promising external (to AWS) solutions like Thundra, Epsagon or Lumigo, but we did not have the chance to fully try them yet.
Theodo proudly added its tool to the ecosystem: if you want to improve your local development and observability, you should definitely try Serverless-Dev-Tools.
The serverless world is moving fast, very fast. Entering it feels like discovering a brand new universe full of possibilities where everything remains to be built, and it’s exciting!
Now that you understand the basics of serverless architecture
I hope this article gave you some answers! I’d be extremely happy to answer any question you might have and take your feedback to improve the above recommendation.
Comments